簡介
我們已知 Collection 可以儲存多個物件 但如果要做出字典功能該怎麼辦呢? 一本字典有很多單字,以及單字對應的釋義 確實可以用兩個 Collection 去實現 但處理這種映射關係有更好的方式 就是鍵值對(key value pair) 不像 Collection 儲存一個一個物件,而是一對一對物件
會有 key 做為查找的唯一值 以及 key 所對應的 value 只要給定 key 就能在多對物件中找到 value 正如用一個單字在一本字典中查找解釋一樣
在 Java 中這樣的資料結構是由 java.util.Map 負責
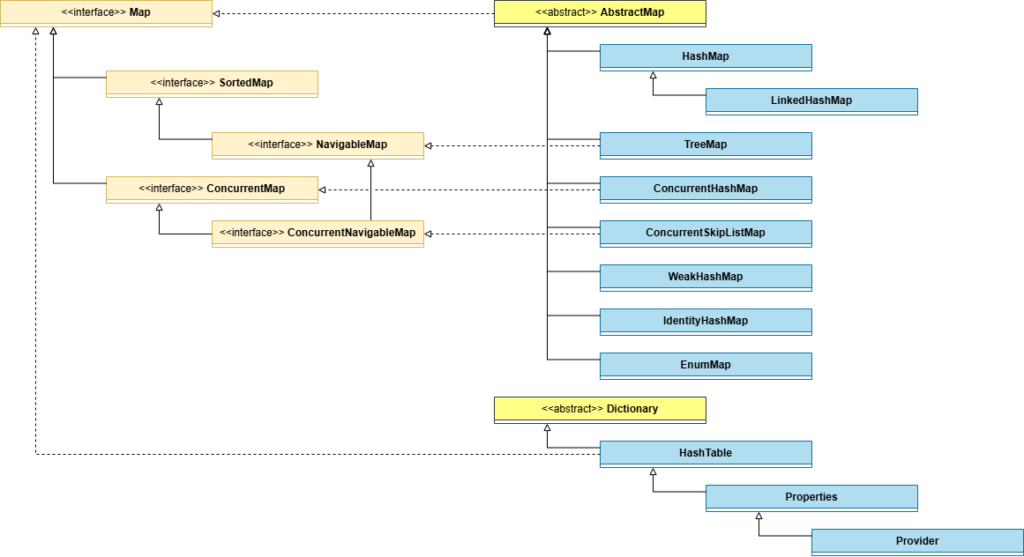
在早期的 JDK1.0 是設計 Dictionary 和 Hashtable 後來 Java2 推出 Java Collections Framework 的概念 由 Map 代表整個家族 AbstractMap 就取代了 Dictionary 成為最基礎的抽象類別
實作方面則擴增了許多功能: 沒有特殊需求的話,高效能的 HashMap 是最常用的 因為 HashMap 無序,若有排序需求則使用實作 NavigableMap 的 TreeMap 因為 HashMap 非執行緒安全,若有並行需求則使用實作 ConcurrentMap 的 ConcurrentHashMap 若又要排序又要並行,則使用實作 ConcurrentNavigableMap 的 ConcurrentSkipListMap
剩下的就比較不常見了
EnumMap 的 key 必須是 Enum
IdentityHashMap 只會比較引用位置(k1==k2)
WeakHashMap 的 key 是會被 GC 回收的
使用
map.put();
map.get();
map.remove();
map.clear();
map.isEmpty();
map.containsKey();
Set keyset = map.keySet();
Set entrySet = map.entrySet();
Collection values = map.values();
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String) o1).length() - ((String) o2).length();
}
});
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String) o2).length() - ((String) o1).length();
}
});
tree 插入時,走訪所有 key 找到適合位置插入
走訪
結論
| 底層 | 執行緒安全 | 順序 | null key | null value | 應用 | |
|---|---|---|---|---|---|---|
| HashMap | Hash table | ✗ | ✗ | ✓ | ✓ | 效能最佳 |
| LinkedHashMap | Hash table + Linked list | ✗ | 插入順序 | ✓ | ✓ | 保留插入順序 |
| TreeMap | 紅黑樹 | ✗ | 排序 | ✗ | ✓ | 排序需求 |
| ConcurrentHashMap | Hash table | ✓ | ✗ | ✗ | ✗ | 並行需求 |
| ConcurrentSkipListMap | Skip list | ✓ | 排序 | ✗ | ✗ | 並行+排序 |
| HashTable | Hash table | ✓ | ✗ | ✗ | ✗ | 已廢棄 |
| Properties | Hash table | ✓ | ✗ | ✗ | ✓ | 讀取配置檔 |
容器的選擇:
- 單個物件:Collection
- 允許重複:List
- 增刪多:LinkedList
- 改查多:ArrayList
- 不允許重複:Set
- 無序:HashSet
- 排序:TreeSet
- 插入順序:LinkedHashSet
- 允許重複:List
- 一對物件:Map
- 無序:HashMap
- 排序:TreeMap
- 插入順序:LinkedHashMap
- 讀取文件:Properties
Can I ask a quick question about your site? https://google.com/?spady
Rospady
What is your question?